
AI's Reliability Gap
High highs and low lows do not a machine God make


1. Introduction
For all the hype about AI, deserved and undeserved, it is a curious fact that AI models’ effects on the economy continue to border on nonexistent. Notwithstanding anticipation of both a white-collar jobs apocalypse and an AI-driven productivity boom, there remains little-to-no evidence for either. Why is AI not substituting for workers in fields like software and translation? Why, if a range of experiments on AI find a mix of self-reported and independently verified productivity speedups, is this not reflected in the macroeconomy?
There are a number of plausible answers. Principal among them is that redesigning workflows around new general purpose technologies is a messy, frictional, uncertain process. AI capabilities remain “jagged,” i.e. much better in some areas than others, meaning it is often unclear, at least prior to costly experimentation, where AI might create real value. AI can also produce convincing facsimiles of high-quality work, creating perverse incentives to bloat code repositories and colleagues’ inboxes with so-called “workslop.” This in turn requires new verification loops to guard against bad AI outputs leaking into comms, codebases, datasets, internal tooling, and outbound products.
For AI maximalists, these represent surmountable challenges. Once firms restructure themselves around the unique affordances of AI—as they once did with electricity—they will begin to see much larger gains. This is the idea of the ‘productivity J-curve,’ that as firms adopt new general purpose technologies, their measurable productivity falls at first due to spending on the ‘intangible capital’ they need to put the technology to work—new organizational models, business processes, tacit knowledge, and so on—but then eventually rises as these investments pay off, hence the upswing of the J-curve.
This may yet occur with AI. Still, the technology is already remarkably capable, and some workers, like software engineers, have already spent considerable time and effort integrating AI into their workflows. Nonetheless, a May study of 100,000 developers on GitHub, Demirer, Yang, and Musolff (2026),found that, while AI coding agents increased coding activity by 180%, they only increased actual product releases by 30%, and had no appreciable effect on app usage across marketplaces like the Apple App Store and Google Play store.
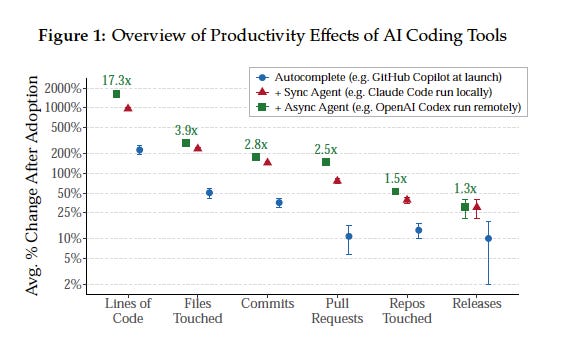
This complicates the J-curve story somewhat, in that software developers either have not had to, or have already navigated many of the adoption frictions slowing AI’s uptake in other parts of the economy, and are still notching modest returns at best. The recent shift toward greater cost discipline by corporates with large AI bills has the same implication: if this spending was a boon to productivity, then it would be paying for itself.
While no doubt aspects of the J-curve story are true, a large survey conducted by Anthropic in December points to another, in some ways more familiar explanation for AI’s limited economic impact. In the “largest and most multilingual qualitative study ever conducted,” a Claude-assisted survey of 81,000 people around the world, Anthropic found that participants’ most commonly cited worry about AI was unreliability, as in “concern about … hallucinations, inaccuracy, fake citations, [and, in a nicely efficient and rhythmic turn of phrase] verification burden defeating the purpose.”
At one level, everyone knows that AI has this problem. All but the technology’s most credulous defenders understand that, at least for more subtle, complex, or ‘out-of-distribution’ questions or tasks, AI’s output is not to be taken at face value. Even if it is often good enough, it is still not something you can lean on if you have real money or status on the line.
As universal as reliability issues are, they are usually treated as a minor nuisance by serious analysts of the AI boom, rather than a deep limitation that stands to shape the technology’s long-term trajectory. I suspect this stems from many in this group becoming so negatively polarized against AI skeptics of the ‘bubble’ and ‘stochastic parrot’ varieties that they have developed an overinclusive allergy to other, more grounded forms of bearishness.
Whatever the reason, questions of AI’s reliability have taken a back seat to questions of its capability. Most analysts are more interested in what AI can do, even if it does those things inconsistently, than they are in what AI does do on average; they are interested in AI’s peak, rather than its typical performance.
But reliability is at least as, if not more important than capability in shaping AI’s real world deployment. And for those who take such questions seriously, whether AI models can consistently achieve the same results, whether they break down under minor environmental perturbations, and whether they avoid costly failure modes are all critical determinants of whether they will disempower or harm human beings at scale.
At its highest highs, AI can do astounding things; no serious person can deny that anymore. And I suspect this will, at some point, show up in the productivity statistics. But AI is also unreliable and the fact of its unreliability will remain a drag on its transformative potential well into the future. The sooner this becomes conventional wisdom, the sooner AI discourse can shed its techno-Millenarian trappings and come into its maturity.
2. AI is currently unreliable
The case for AI’s unreliability is really the case for two claims: that AI is currently unreliable, and that it will remain unreliable. A recent paper makes a strong case for the first claim. In “Towards a Science of AI Agent Reliability,” Rabanser et al. (2026) break reliability down into four dimensions inspired by safety-critical engineering research in fields like aviation and nuclear power:
Consistency: Does the system behave the same way when run multiple times under identical conditions, or are outcomes highly variable?
Robustness: When operating conditions deviate from nominal, does the system degrade gracefully or fail abruptly?
Predictability: Can the system recognize when it is likely to fail?
Safety: When failures occur, how severe are the resulting consequences?
After operationalizing these dimensions of reliability (p. 3-5), the authors measure them across two benchmarks—GAIA and τ-bench—alongside raw accuracy. Their main result is that reliability trails accuracy by a large margin, and fails to improve at all along certain sub-dimensions as models become more advanced (p. 6-8).
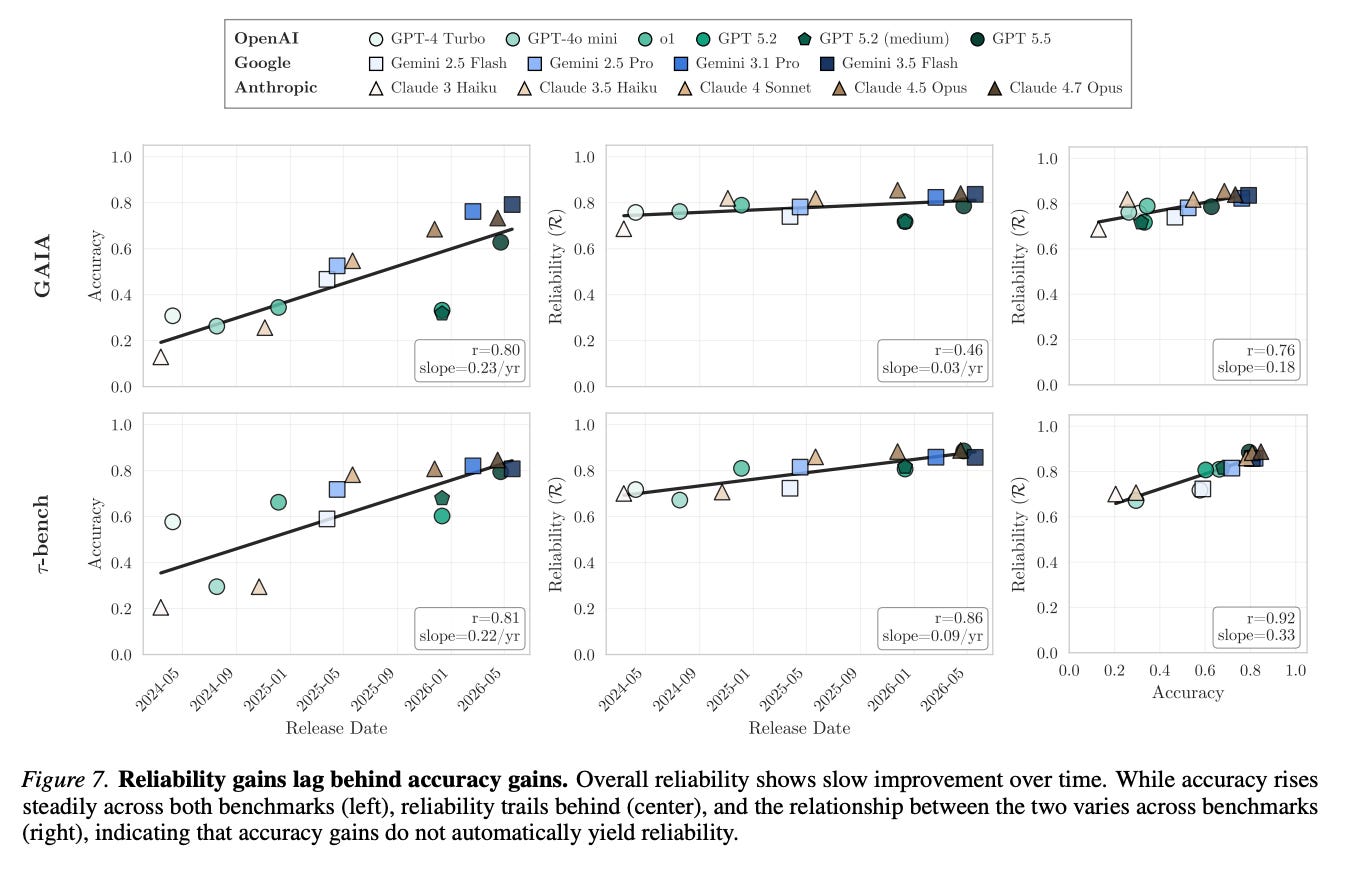
Some specific reliability deficits include AI agents failing to understand minor changes in naming conventions or data formatting, misrepresenting their relative odds of succeeding at different task types, and making financial calculation errors during customer service tasks.
Even frontier models—GPT 5.5 and Claude Opus 4.7—committed medium to high-severity safety violations, such as failing to “[protect] personal data, [refrain] from unauthorized actions, or [stay] within boundaries” (p. 4) on, respectively, 6% and 12% of all tasks (p. 50).
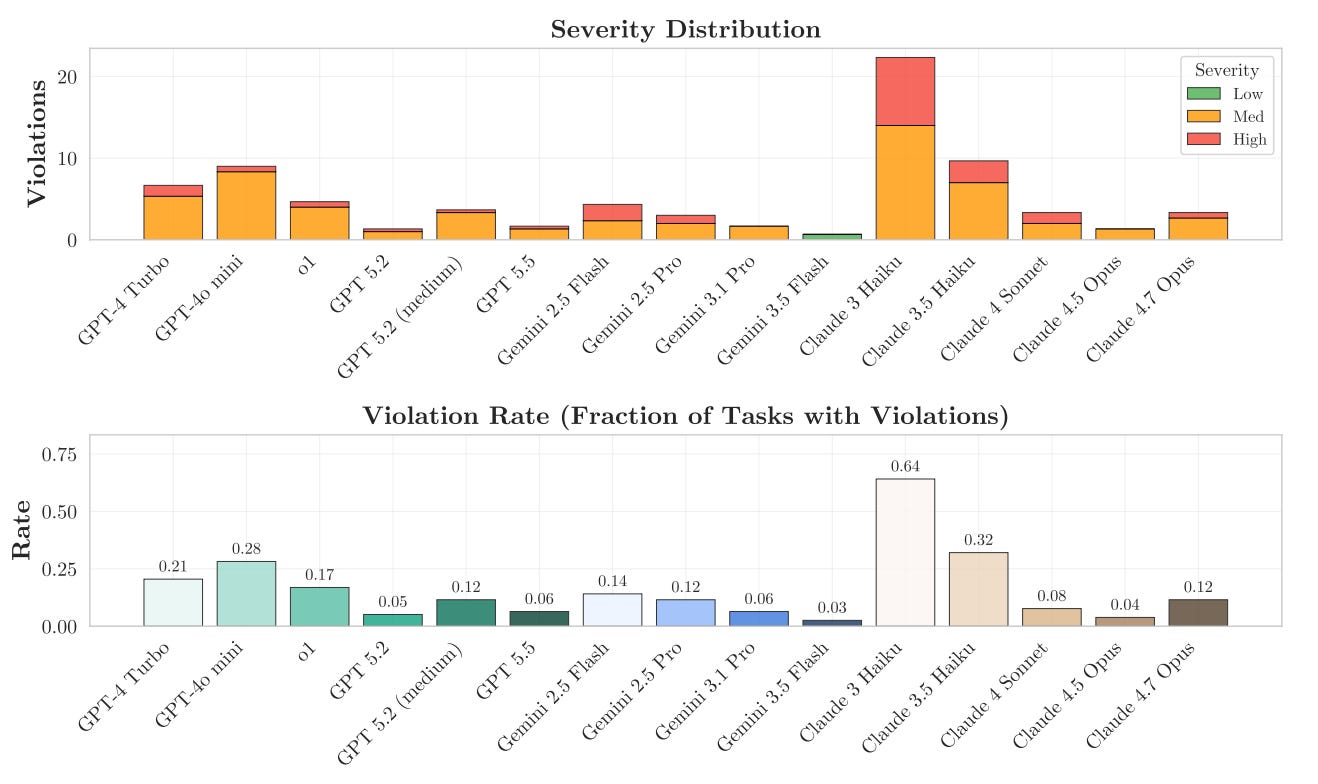
The moral of Rabanser et al. (2026) is that rising average performance may obscure inconsistency, oversensitivity, unpredictability, and even catastrophic failure modes, all of which make real-world deployment much riskier than often appreciated.
Of course, this is just one paper, and it measures AI models’ reliability against two benchmarks only. It is tentative, but not decisive evidence of models’ unreliability. Fortunately—and I’ll add that its striking how few people are aware of this—there has been an explosion of high quality, reliability-oriented benchmarks in just the past six months measuring everything from whether AI agents produce secure code to whether they can judge when to ask their human users for help. Almost across the board, they reinforce rather than detract from Rabanser et al.’s concerns.
Interpreting these benchmarks requires a bit of preliminary context. Some report two different performance metrics: pass@k and pass^k (“pass at k” and “pass hat k”). Pass@k scores report models’ odds of completing a given task successfully at least once across k trials. This is what most benchmarks report. Specifically they report pass@1, the odds a model completes each task on a given run, averaged across all tasks, and sometimes across multiple runs. This is often just called “accuracy,” and is more-or-less the same as 'the percentage of questions the model got right.’
Pass^k scores are more stringent: they report models’ odds of completing a given task successfully every time across k trials, and therefore register additionally helpful information about models’ consistency. If a model succeeds at some task 80% of the time, then its pass@1 is 80% and its pass@4 is 1 - (0.2)4 ≈ 99.8%. But its pass^4, the chance it succeeds all four times, would only be (0.8)4 ≈ 41%.
The convention of reporting pass^k in addition to pass@k originates with Yao et al. (2024), the first iteration of the τ-bench series of benchmarks, and stems from acknowledging that, for most economically valuable tasks, it is important that agents succeed consistently over repeat trials, rather than only sometimes. As a result, many benchmarks now report both pass@k and pass^k.
This context in mind, below is a sampling of 10 recent benchmarks showing AI models and agents to be far from reliable enough to perform most white-collar work (though note that some are more up-to-date than others):
τ-bench Banking: “[evaluates] AI agents in knowledge-intensive customer support. It pairs a realistic fintech knowledge base (698 documents across 21 product categories, ~195K tokens) with tasks requiring multi-step reasoning, policy application, and tool use. The best model, GPT 5.[5] with high reasoning, achieves only ~[37]% pass@1 [and ~21% pass^4]. Current frontier models still fail at retrieving, interpreting, and acting on messy real-world documentation.”
CAR-bench: “evaluates LLM agents as automotive in-car voice assistants across 254 public tasks spanning three complementary dimensions: Base multi-turn task completion (100 tasks), Hallucination limit-awareness under missing capabilities (98 tasks), and Disambiguation uncertainty resolution of ambiguous requests (56 tasks). Agents interact with an LLM-simulated user, plan and chain calls across 58 interconnected tools governed by 19 domain-specific policies, and operate over large-scale world data (48 European cities, 130K+ POIs, 1.7M+ routes).” Claude Opus 4.6 currently tops the leaderboard with a pass^3 of 58%.
Human-in-Loop-Bench: a benchmark that withholds information agents need to complete tasks and measures whether they notice, retrieve said information by asking a simulated human user, and go on to successful completion. It includes two domains: software-engineering and text-to-SQL. Tasks are drawn from the SWE-Bench Pro and BIRD benchmarks, and are modified to include “blockers,” i.e. “missing information, ambiguous requests, or contradictory information.” To complete tasks, models have to recognize blockers and ask for clarification before proceeding. The current top scorer is GPT 5.5 with a pass@3 of ~29%. As of the initial publication of HiL-Bench, pass@3 was ~75-89% across all models with complete information, but only 4-24% with blockers.
SWE Atlas: “a benchmark for coding agents spanning three professional software engineering workflows: Codebase QA (124 tasks), TestWriting (90 tasks), and Refactoring (70 tasks). SWE Atlas differs from prior SWE benchmarks in three key ways: it targets underrepresented but practically important task categories, uses comprehensive category-specific evaluation protocols, and adopts under-specified, agentic task formulations that better reflect real-world usage … even top models consistently struggle with subtle edge cases, complex runtime analysis, and adherence to software engineering best practices.” The top scorers, GPT 5.5 (Codex), GPT 5.4-xHigh (Codex CLI), and Claude Opus 4.7 resolve only 44-49% of tasks (i.e. have a pass@1 of 44-49%).
FACTS: “[evaluates] the ability of language models to generate factually accurate text across … four sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models’ world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents.” The current top scorer is GPT 5.5, with an average pass@1 across all four leaderboards of ~71%.
TaxBench: “[evaluates] how well AI models perform on real-world tax tasks—including tax knowledge and judgment, tax calculations, and agentic question answering—built from real client questions and documents drawn from active tax workflows inside Rivet.” The current top scorer is GPT 5.5 Pro with a pass@1 of ~78% and a pass^5 of ~29%.
SusVibes: evaluates 22 model and harness combinations on 200 real-world vulnerability tasks from open-source Python projects, measuring both functional correctness and security. The current top scorer is Cursor + Claude Fable 5, which achieved a pass@1 of 72.6% on functional correctness, but only 29% on security, meaning only around a third of generated code was safe to ship.
SciConBench: evaluates whether frontier models and deep research agents can synthesize scientific conclusions from open-web evidence by constructing and administering 9,107 question-answer pairs from the Cochrane Database of Systematic Reviews. Answers are assessed by expert-validated LLM-judges for factual accuracy, coverage, and overall quality. Across the 8 models and agents evaluated (GPT 5.1, Claude Sonnet 4.5, Gemini 3 Pro, Ai2’s Dr. Tulu, OpenAI’s o3-deep-research and o4-mini-deep-research, and Perplexity’s sonar-deep-research and sonar-reasoning-pro), the top scorer was o3-deep-research with an overall quality score of only 33%. Across all models and agents “44-84% of generated conclusions contained at least one fact contradicting the reference CDSR review, and nearly all contained at least one fact not supported by the reference review” (p. 8).
LOCA-Bench: evaluates agents’ complex retrieval and reasoning, instruction following, environment exploration, and hallucination propensity across increasingly large knowledge-work environments to assess how performance degrades as context grows. Task success was graded as a binary based on scripts comparing agents’ final environment states to ground-truth environment states. As of publication in February, the top scorer was Claude Opus 4.5 whose pass@1 degraded from 96% at 8K tokens of context to 14.7% at 256K tokens of context.
AA-Briefcase: evaluates agents’ ability to complete realistic long-horizon knowledge-work projects, made up of discrete sub-tasks requiring shared institutional context. Tasks are designed by industry experts across data science, product management, banking operations, heavy industry strategy, and due diligence. Evaluation combines a binary rubric, with pairwise comparisons for both analytic quality and presentation. The current top scorer is Claude Fable 5 with a pass@1 of only 3%.
There is a lot here to sift through, but these results are jointly sufficient to show that current AI models are not prepared—as it stands—to handle the vast majority of knowledge work.
That this is so is evident in the increasingly long list of AI-related gaffes embarrassing everyone from top law firms to award-winning authors, as well as in survey-based studies of real-world AI use, which reflect a low degree of trust in agents’ ability to work autonomously. Despite what an unreflective read of METR’s Long Tasks Benchmark would imply about agents’ long-horizon capabilities, Pan et al. (2026) found (as of February) that 68% of agents in real production environments executed at most 10 steps before human intervention, and 93% served human end users, rather than other agents, or non-agentic software systems.
All attempts to anticipate the future of AI must begin with this fact: AI models are still not reliable enough to be delegated anything even moderately complex within enterprises, at least not without costly oversight and verification. Put another way, for most white-collar workers, and for most tasks, it is not the case that you can assign an agent that task and expect it to be done to your satisfaction. No amount of flashy demos on X, fawning interviews with frontier lab employees, or FOMO-driven hype cycles is going to change that. As the evidence currently stands, there is still a large gap between what we would like AI to do and what it typically can.
3. The capability streetlight
If this is true, though, it is puzzling why so many smart, informed people are convinced of claims that presuppose otherwise. One would be the surprisingly common claim that AI could soon automate much white-collar labor, as well as the claim it is on track to becoming so powerful that it could, intentionally or not, cause the extinction of the human race.
As it stands, the best evidence that we have on AI models’ performance in realistic environments is not even close to supporting these conclusions. And it is far from clear whether the best evidence that we have in five years, or even ten will support them either—more on that later.
For many following developments in AI, though, this amounts to hearsay. To suggest that such extraordinary transformations as the near-term automation of all knowledge work are implausible amounts, in some circles, to a kind of reality-denial. It is to make the oft-mocked, oft-disproven claim that “deep learning has hit a wall.” While our forecasts seem surprising, say the AI maximalists, what we have done and you, the lowly skeptic, have not is transcended the human brain’s bias against exponential growth and internalized (in another of their favorite stock phrases) that AI “is the worst it’s ever going to be.” His sproutlike ancestors may have their flaws, but make no mistake: the world-eating machine God is deceptively soon to arrive.
Putting aside the grating meme-cum-argument engagement style of much of the techno-Millenarian cohort, there are some very smart people among this group. While some doubtless have too much pride to admit being wrong, others I expect are anywhere from three months to a year away from admitting they have fallen victim to just the confusion I am at pains to correct: capability is not reliability, and while the former has advanced at a rapid pace, the latter is something we have only just started to measure. Nor do we yet know how reliability scales, and insofar as reliability and capability are genuinely distinct constructs—a case made in detail by Rabanser et al.—it is a mistake to assume that the one will behave just like the other.
Consider Epoch AI’s capabilities index, which shows a smooth, though recently quickening upward trend.
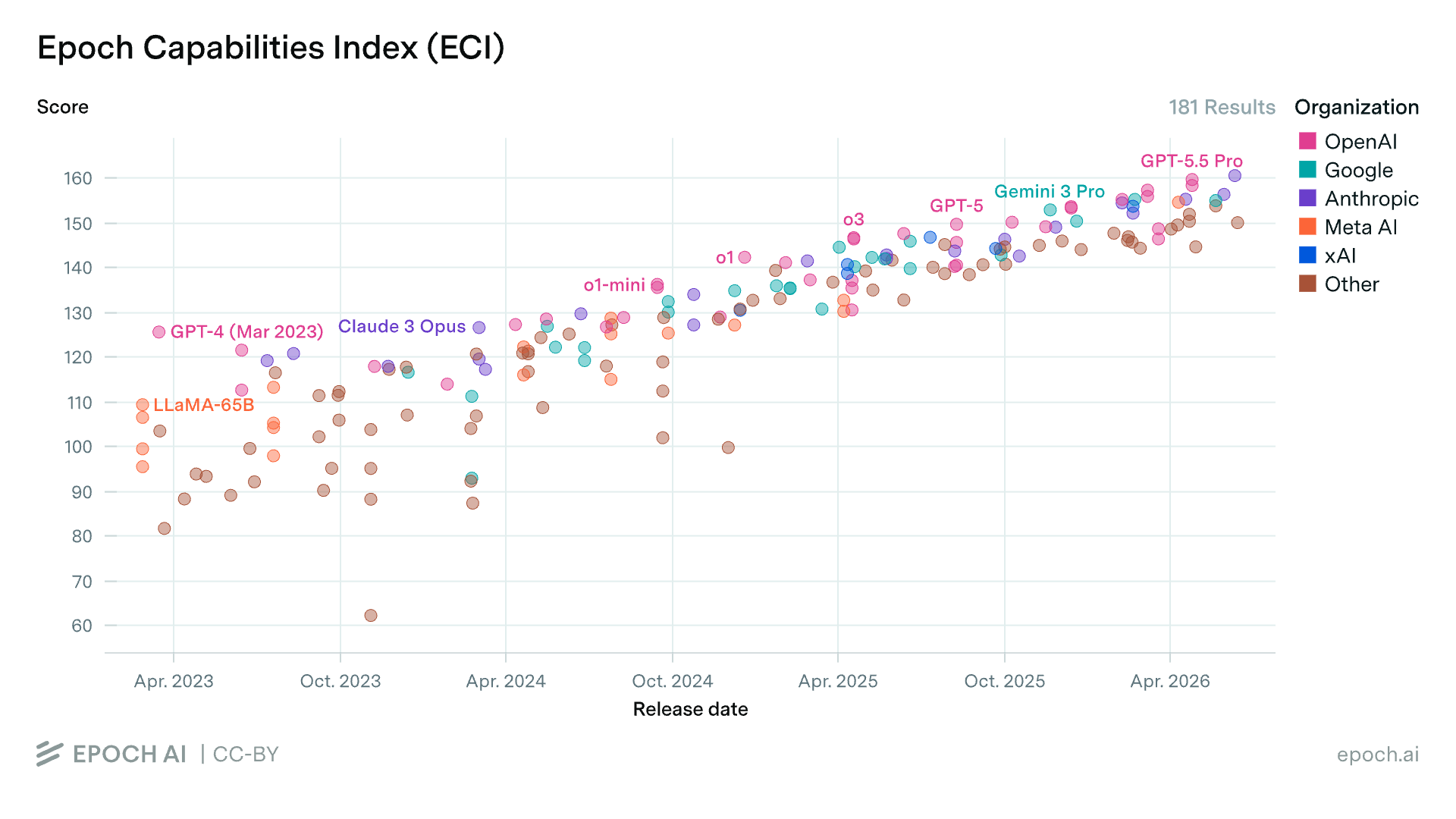
Despite its name, it is rarely if ever appreciated that the ECI is a measure of capability, not reliability. The vast majority of benchmark scores fed into the index are simply the proportion of tasks models succeed at, on some well-defined success/failure binary, averaged over some n of runs—i.e. the pass@1. Recall that pass@1 can only tell us so much about models’ reliability; that a model completes, say, 90% of tasks on some benchmark does not tell us whether it does so consistently, robustly, predictably, or safely. Pass^k is at least informative about the consistency piece.
None of the benchmarks in the ECI report pass^k, much less whether models buy high performance at the cost of insecure code, or are hypersensitive to minor perturbations in prompts or context. Not only that, but the ECI is explicitly designed to “capture the upper end of each model’s capabilities” by aggregating across different evaluation settings and taking the highest score per benchmark. This is not objectionable in-and-of-itself, but it does make the ECI much less useful than often appreciated for forecasting AI’s wider political-economic impacts, which hinge just as much on typical as they do peak performance.
While the ECI in informative for what it is, what we also need is an ERI—an index of models’ reliability, one that aggregates benchmarks with a high degree of realism, and uses a multidimensional evaluation framework aggregating consistency, robustness, predictability, and safety à la Rabanser et al.
This could go a long way to solving what I claim is a classic, if in this instance enormously consequential case of the streetlight effect: until this year, the AI community writ large has tried to understand what AI models can do via the benchmarks it is easiest to create, those made up of isolated, well-defined tasks with easy verification. The problem of course is that not only are these the easiest sorts of tasks to post-train AI models on, given their verifiable reward signals, but they also leave out so much of what is distinctive to real white-collar work: navigating ambiguity, performing consistently and predictably, doing high-level planning and orchestration, tracking tacit and codified institutional knowledge, coordinating with other humans, complying with norms, rules, and regulations, and so on and so forth.
This, then, is the explanation for the gap between AI’s real-world performance and its theorists’ predilection for science-fictional over-extrapolation: they have treated the light under the streetlamp as gospel, and run flailing into the dark.
4. AI will (probably) remain unreliable
That AI is unreliable now is one thing. But It remains to defend the far more uncertain half of the case for AI’s reliability problem—that AI is not only unreliable now, but will remain unreliable well into the future. It is important to be honest up front that this is impossible to do with any real confidence. We have even less evidence to anticipate the trajectory of what we might call ‘reliability scaling’ than we do capability scaling. But we do have some.
In what follows, I have taken the approach of identifying some stylized facts about progress in capability that plausibly have implications for progress in reliability. It is best to treat them as constraining possibility space, rather than as implying that your preferred AI future will or will not occur.
To that end, consider the following claims about AI capability, which though occasionally controversial are, I think, well-supported.
First, on standard capability benchmarks, accuracy—i.e. pass@1—mostly scales as a sigmoid against exponentially rising compute (Owen 2024, Ruan, Maddison, and Hashimoto 2024). In other words, to get roughly linear gains on average (until saturation hits), compute stock needs to grow exponentially.
Second, since the launch of ChatGPT in 2022, effective compute stock (accounting for algorithmic efficiency improvements) has grown exponentially, and by around an OOM per year at that (Genewein et al. 2026, p. 3). Over four years, that would be a 10,000x increase in effective compute (with large uncertainty bands in both directions). While capability gains since 2022 have been impressive, they are arguably not as impressive as one might expect given the enormous amount of compute that has come online in the interim.
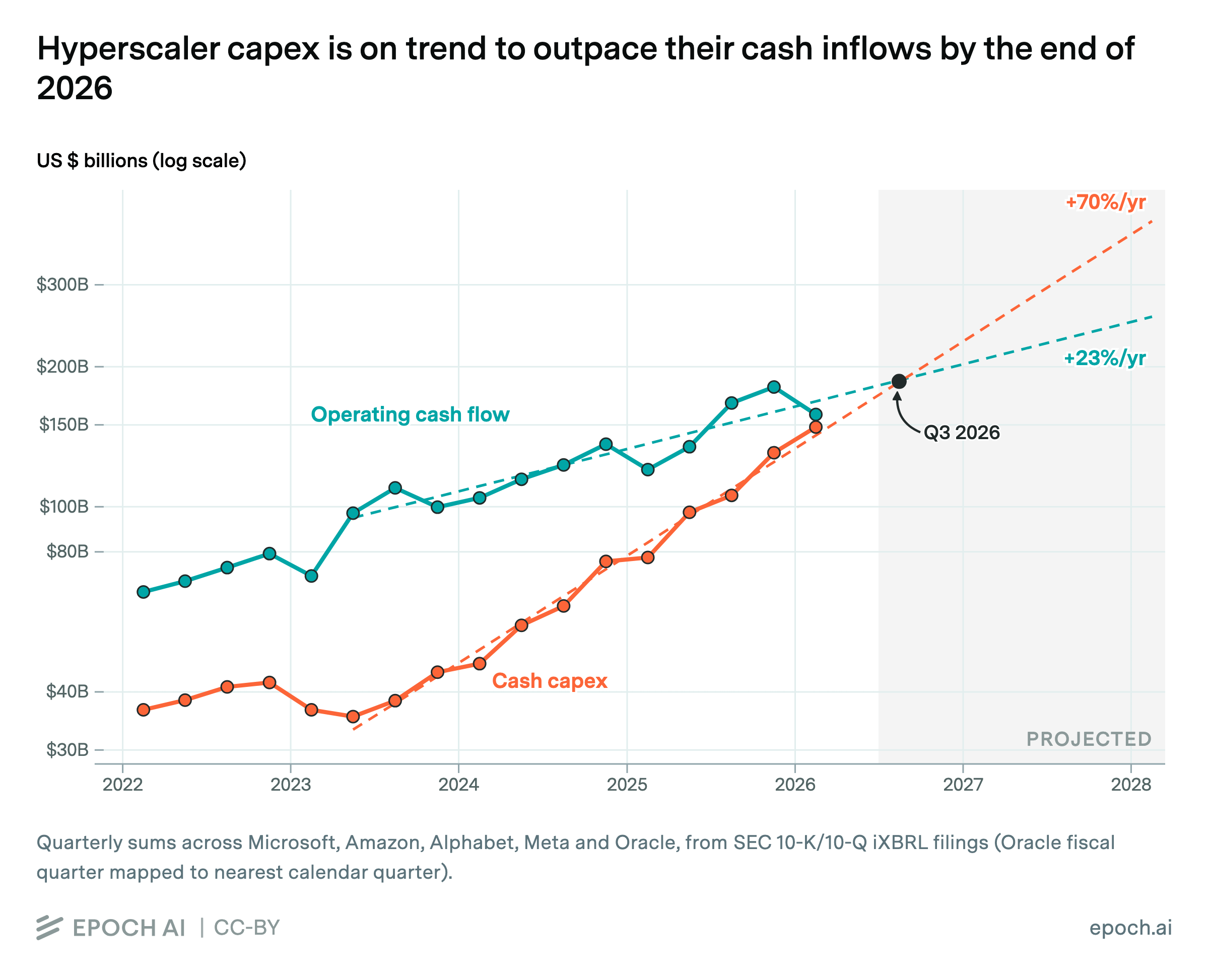
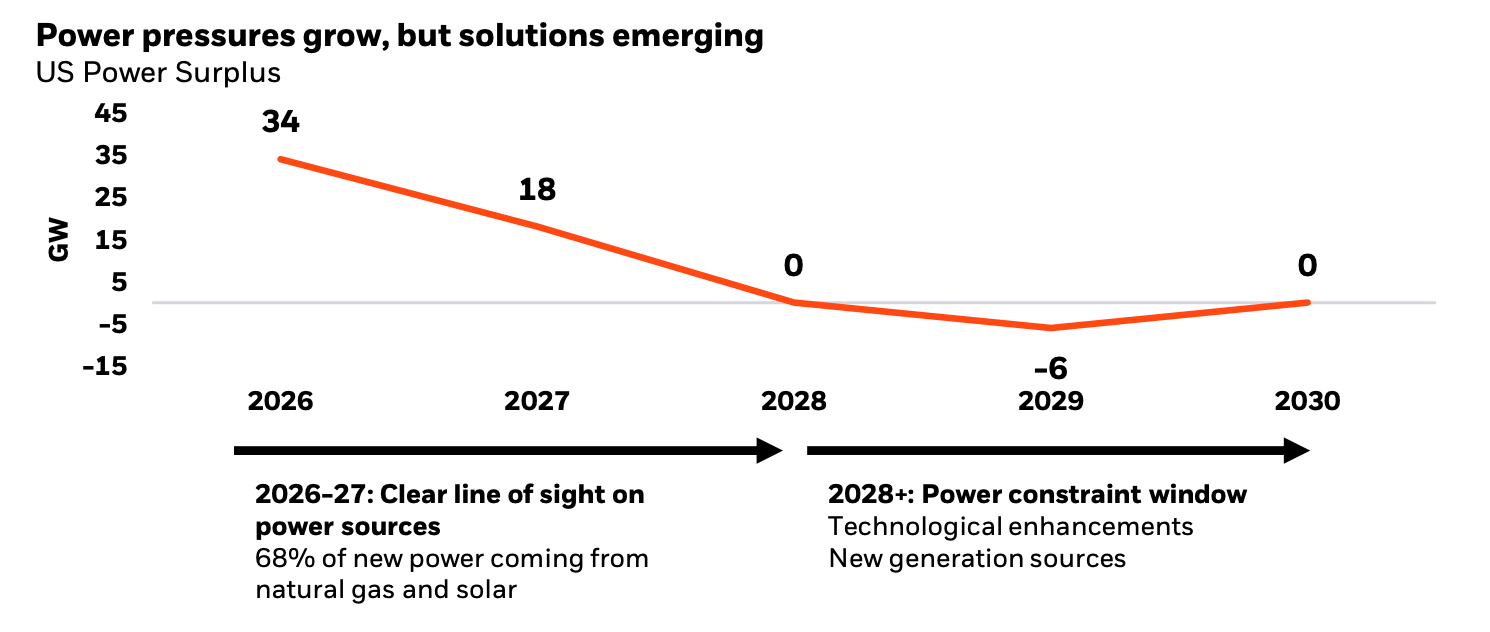
Third, it is unclear how long compute can expand at its current pace, given both financing constraints and major infrastructural bottlenecks. Hyperscalers’ capex expenses are set to outpace their operating cash flows by Q3 of this year, meaning the data center buildout will depend more so than before on the already cautious appetites of external investors. Likewise, AI-related demand for power is set to outpace available capacity in the US by 2028, meaning that continued scaling will depend on our famously limited ability to bring new generation sources online.
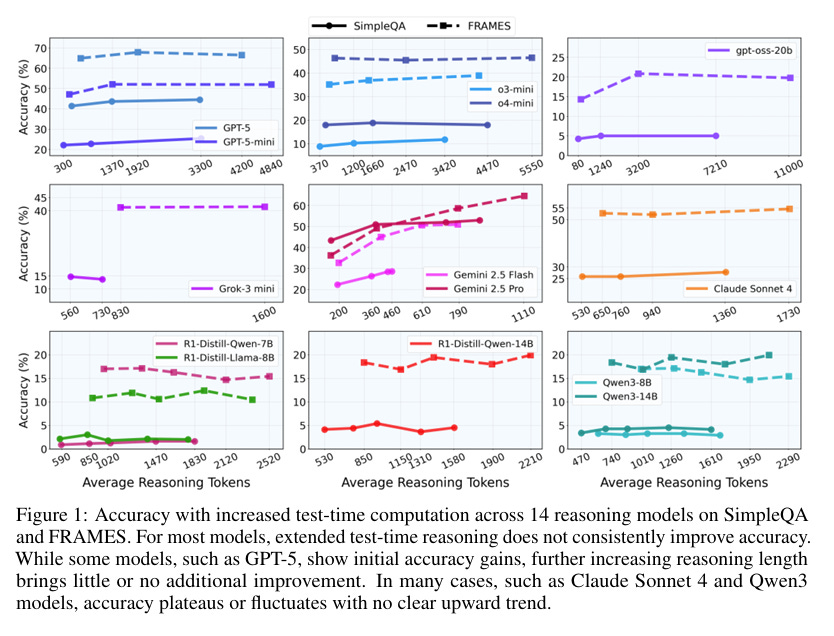
Fourth, capability gains since late 2024 have disproportionately come from combining reinforcement learning with verifiable reward (RLVR) with much higher inference, or test-time compute. RLVR and inference compute scaling generally show the same roughly log-linear relationship with benchmark performance as pre-training compute (Brown et al. 2024, Khatri et al. 2025). However, this relationship only holds for verifiable domains like math and coding and collapses in other knowledge-intensive domains (Zhao, Hooi, and Ng 2026; Liu et al. 2026). In other words, outside of math and coding, deploying more compute for RLVR and inference is not likely to produce major capability gains.
However, this could change as labs begin to train models on increasingly sophisticated reinforcement learning (RL) environments for harder-to-verify enterprise tasks like UI manipulation or financial modeling (although it would be the environments themselves rather than compute per se responsible for any new capabilities that result). That said, the extent of prospective gains from these environments is unclear. It is worth taking a brief detour to discuss some of their limitations.
One challenge for RL outside of coding and math (or more ambiguous tasks within coding and math) is that most tasks lack well-defined success conditions, and even those that do often admit to a range of solutions that workers have conflicting preferences over. This last point is woefully underdiscussed: frontier labs have the unenviable task of encoding model behavior that pleases every possible user at once. But since users have legitimate disagreements over what constitutes the right behavior, models will fall short for many of them on some tasks. Context engineering can solve back for this to an extent, but is subject to the length-limitations of context rot; some preferences are also implicit or otherwise challenging to codify in text, so this is not a panacea.
Another more overarching challenge for progress in RL is that businesses change, as do industries and even whole economies. This raises the specter of a costly whack-a-mole dynamic whereby expensive RL training runs are obsolesced before they can be made useful. In general, the idea that every or nearly every white-collar task can be made verifiable, and that training on these verification signals can keep up with the always-changing nature of knowledge work is questionable at best. If I am a clever human, I can learn a new task in a few days or hours. If I am an AI model, it may take months, not to mention millions of dollars.
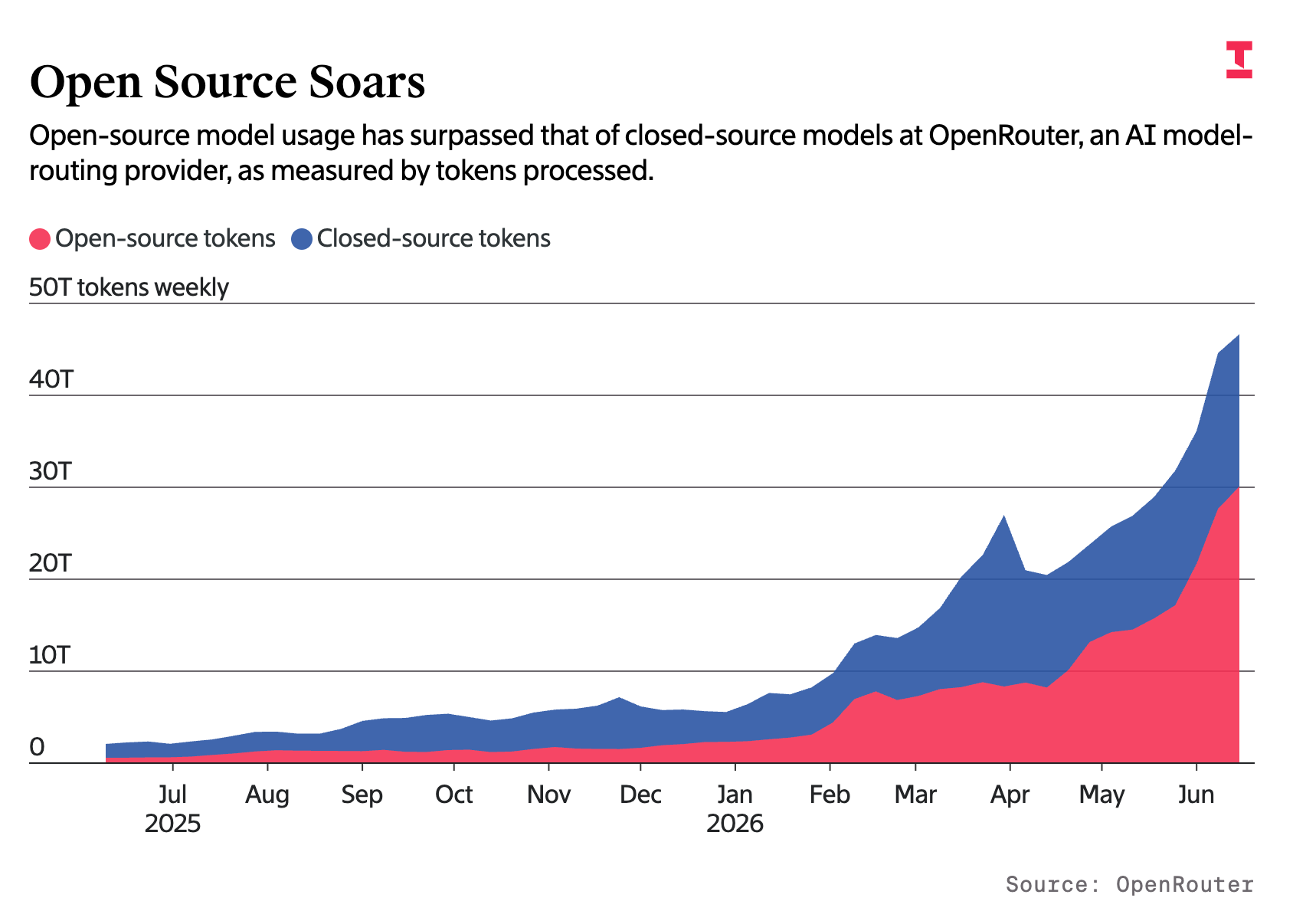
Returning to our higher-order list of stylized facts about capability scaling, the capabilities of open source models are rapidly catching up with major proprietary models. Some analyses now put the best among them, such as the new GLM 5.2, around three months behind the frontier. That end users, especially ones in enterprise, could begin substituting open for closed models en masse—a process that has already begun—represents a serious threat to frontier labs’ businesses.
Finally, and most importantly, the Trump administration’s recent suspension of foreign, and in practice all access to Anthropic’s Claude Fable 5, even if reversed, will force labs to approach capability scaling with much greater caution, so as to avoid similar restrictions on their own Fable and post-Fable class models. It may also portend the rise of a more complex licensing regime that could slow frontier deployment. This could in turn create heightened financial risk for labs, to the extent they need to continue serving better models at a certain pace to keep up with their liabilities.
Taken together, and notwithstanding substantial uncertainty, these considerations suggest that the modal view of AI capability progress ought to be more bearish. I would emphasize in particular the unclear returns to further post-training outside of coding and math, and just how different the world is post-Fable-suspension.
Before Fable, the public at large could expect to gain from further capability progress, and the labs could expect to gain from public feedback, helping them to further improve their models in a virtuous circle. If the new status quo is such that every subsequent model is restricted to a narrow set of licensed users, or only released conditional on onerous security restrictions and data retention policies of the kind Fable users complained about prior to its suspension, then the idea of automating white-collar labor seems dead-on-arrival. Even accounting for some capability overhang, pre-Fable models cannot automate much if any white-collar labor on their own, and in this scenario, newer models would be some mix of inaccessible and intractable for enterprise use.
If future capability gains are consequently more uncertain than often appreciated, future reliability gains would be even more so. That is because, in addition to Rabanser et al. (2026)’s result that reliability growth (as they define it) trails capability growth on GAIA and τ-bench, comparing across other reliability and capability-oriented benchmarks—while a bit different than comparing distinct measures of reliability and capability on the same benchmarks—shows similar gaps.
To give just a couple of examples (chosen because they are the only benchmarks of my earlier list with sufficient data spanning the previous year), below are graphs of models’ pass@1 performance on τ-bench Banking and FACTS by release date, alongside the same models’ performance on Artificial Analysis’s Intelligence Index, a weighted average of benchmarks “tracking progress toward artificial general intelligence across mathematics, science, coding, and reasoning” (the specific benchmarks are GDPval-AA v2, 𝜏-bench Banking, Terminal-Bench v2.1, SciCode, Humanity’s Last Exam, GPQA Diamond, CritPt, AA-Omniscience, and AA-LCR). Recall that τ-bench Banking and FACTS measure, respectively, AI agents’ ability to navigate and complete complex customer support tasks using a realistic fintech knowledge base, and models’ overall factual accuracy across image-, internal memory-, web search-, and document search-based questions. They do not of course cover all relevant dimensions of reliability, but better isolate it than does the Intelligence Index in aggregate.
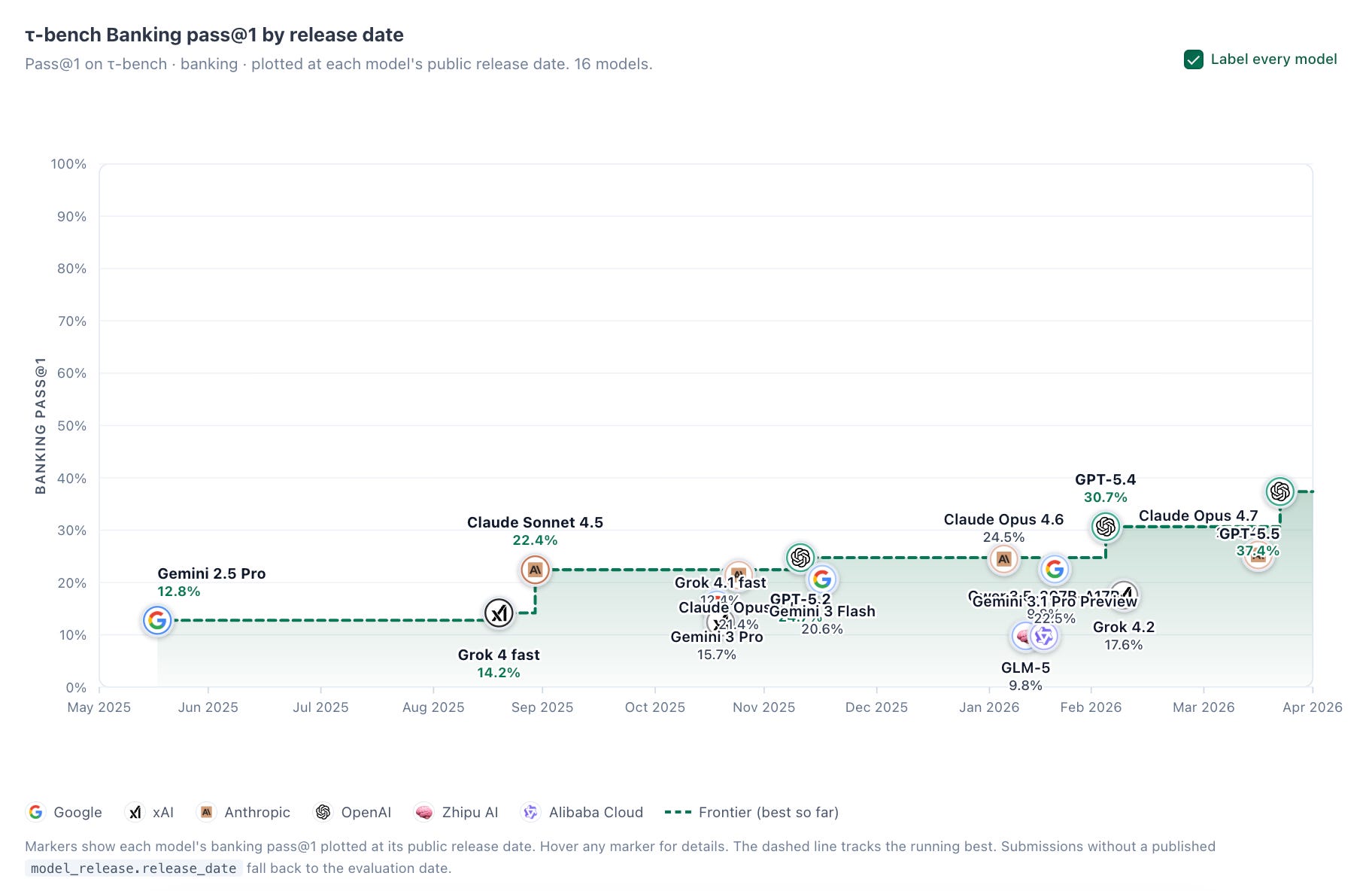
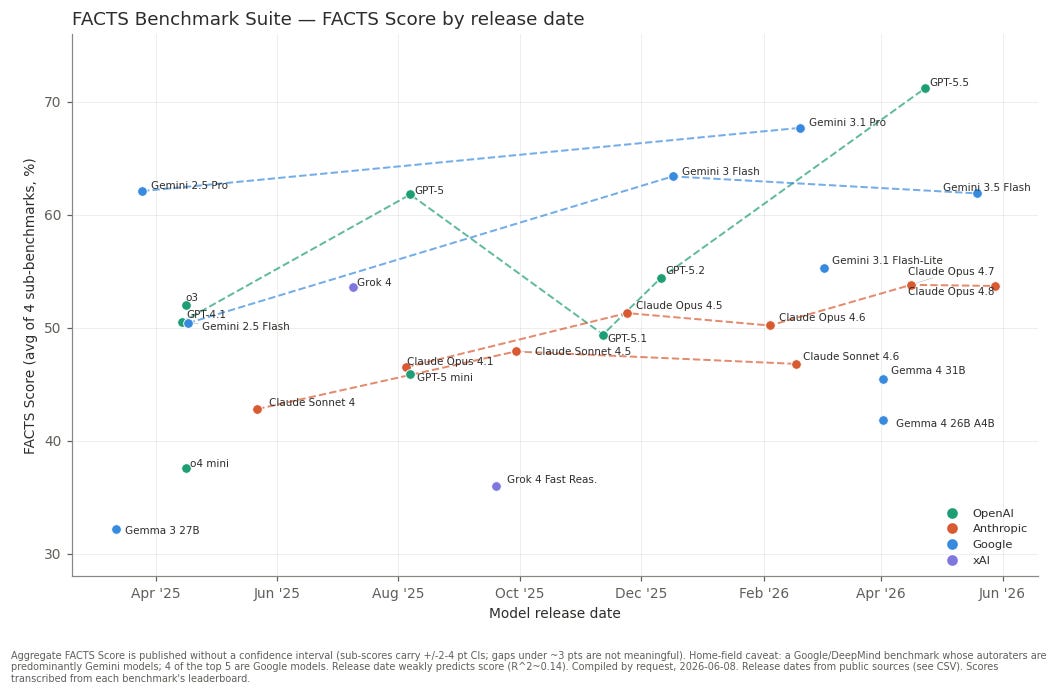
Gains within model families on FACTS and τ-bench Banking, with the partial exception of GPTs 4.1 through 5.5 on FACTS, are much more modest than analogous gains on the Intelligence Index, as well as the ECI (this is a bit hard to eyeball, so follow the links and explore yourself). And while I’ve previously argued that it should be discounted for methodological reasons, it is worth noting that time horizons on METR’s Long Tasks benchmark over this same period rose from ~2 to ~12 hours.
What limited evidence we have, then, is probably sufficient to infer that reliability scales slower than capability across most plausible operationalizations of both concepts. While models have become much better at a wide range of general-knowledge, math, coding, and reasoning tasks, they have improved much less on benchmarks that simulate realistic knowledge-work.
Combined with the fact that they perform poorly at this work now—no model is even close to getting one ‘9 of reliability’ (i.e. 90%) on the benchmarks summarized in section two (on pass@1, much less on pass^5, or 10, or 20)—the modest pace of recent progress on reliability, plus the challenges labs face in continuing to scale make it doubtful that AI models will automate or otherwise displace most white-collar labor in the foreseeable future. And if they cannot do that, they are certainly not going to string together thousands, or even millions of high-precision, high-stakes executions necessary to take over the world or melt us down for paperclips.
5. Conclusion
It is an unfortunate feature of the public debate around AI that many of its influential participants have poor epistemic hygiene. In particular, there is a large and powerful contingent of thinkers hailing, ironically, from the rationalist and effective altruist communities, who believe and have convinced many others to believe that the arrival of AI portends a top-to-bottom transformation in the human social order, one that will either solve our most unyielding problems—cancer, climate change, mortality—or bring about our ultimate demise.
Views of this kind tend to have two overarching weaknesses: first, they rarely engage, or fail to engage thoughtfully with second-order questions surrounding how states, markets, and cultures will react to AI. Even when such factors are considered, AI alone is treated as having the agency to reshape these institutions; commensurate agency is rarely if ever attributed to the institutions themselves, despite their being much vaster, richer, more complex, and more adaptable than AI could ever hope to be. If there is any silver lining to the Fable debacle, it is that it will remind those who have so far ignored it that the state is not to be treated as an analytical afterthought, even for the sake of forecasting AI’s capabilities, much less its wider social effects.
The second weakness of much AI maximalism, which is more to the point of this article, is its often superficial engagement with questions of how capable, and how reliable AI models are in practice. Proponents of these ideas tend to place more weight on anecdata from power users than methodologically sound benchmarks. At the same time, they brush off anecdata from anyone who expresses frustration or dissatisfaction with AI’s performance, and assume without argument that the technology’s so-far underwhelming economic effects are indicative of temporary frictions rather than long-term limitations.
Condensed into a single provocation, my question for the archetypal maximalist is this: if AI (in the guise of LLMs) has been unreliable since its inception, has remained highly unreliable even modulo large capability gains, and has done so despite the effective compute stock of AI chips rising by ~10,000 times, why believe that AI will automate white-collar work in the near, or even medium-term? How is AI supposed to automate whole jobs, when it is not even close to one 9 of reliability on realistic white-collar tasks? And even if this could change in principle, why think investors will eat multi-billion dollar losses for years on the uncertain hope that it will?
The economist David Autor once wrote that “if a traditional computer program is akin to a classical performer playing only the notes on the sheet music, AI is more like a jazz musician—riffing on existing melodies, taking improvisational solos and humming new tunes.” As delightful as such performances sound, they do not speak to the sort of disposition that can be trusted to handle critical business processes, much less execute on supervillainesque plans for world domination.
I am more than a little uncertain whether that will change, as anyone paying attention should be. But others are very certain it will, and yet seem to have scrupulously avoided the large volumes of evidence suggesting otherwise—including, but not limited to nearly all of the benchmarks with any degree of external validity, and the minimal effects so far of AI on the white-collar economy. This does not mean that AI is a bubble or a scam, but it does mean that it continues to have serious limitations trillions of dollars and millions of man-hours have made much less headway on than conventional wisdom would have you believe. If nothing else, it is time to start asking when, how—and if—AI will close its reliability gap.
I've followed your takes on AI development with interest for a while, but this piece is just another level. Easily the best analytical piece within the broad "AI future" field I've read in a long time. This is the kind of healthy AI skepticism we need more of - and there are still many more avenues to explore. Kudos!
I suspect the answer to AI unreliability is more AI. LLMs mimic humans, and humans are unreliable. How do we manage human unreliability? More humans.
The software industry is (maybe for the first time ever) a model here. Almost always when software fails it is because a human made a mistake. The software industry is built around processes of testing and review that screen errors down to an acceptable (but far from zero) level, and then react to address further errors as they appear. Almost the entire software lifecycle, except the tiny fun part at the start, is about addressing human cognitive failure.
Within that process there are multiple different human roles, but each of those roles can be formalized as encoding informal language into code or decoding code into informal language, so each of those roles can, potentially, be played by an LLM. Will they be as good as humans? Definitely not as good as the best humans. But will they be acceptable? Probably. And they're much faster, so to some extent you can replace ability with iteration speed. And if you have different models with only limited shared context writing specs, writing code, writing and running tests, doing hands on testing, filing bugs and reviewing code, and you do it faster than humans would be able to do it, is the net result as reliable as a human result? I don't see why it shouldn't be.
I have a suspicion though that the cost of inference is still too high though. Where we stand right now we could easily double the fully loaded cost of a developer if we let them use as many tokens as they might want to automate their whole workflow.